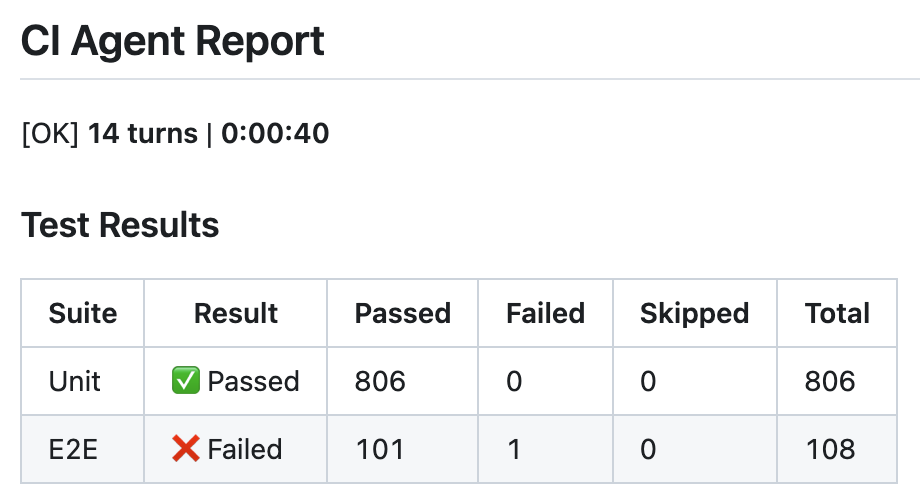
· 5 min read
.NET 서버 CPU 최적화 — 틱당 0.6ms를 0.15ms로 줄이기 Optimizing .NET Server CPU — From 0.6ms to 0.15ms per Tick
.NET 게임 서버의 틱당 처리 시간을 0.598ms에서 0.151ms로. 프로파일링 도구부터 만들고, 병목 4개를 순서대로 잡은 이야기. Cutting a .NET game server's per-tick time from 0.598ms to 0.151ms — building profiling tools first, then systematically eliminating four bottlenecks.
지난 글에서 메모리를 잡았다. 이번엔 CPU다.
문제
Aethelgard 서버를 HeadlessRunner로 돌려봤다. 틱당 평균 0.598ms. 당장 터지는 수치는 아닌데, 엔티티가 늘어나면 이야기가 달라진다. 어디가 느린지는 모르겠고, ECS 시스템이 수십 개 돌아가니까 감으로 찍기도 어렵다.
Aethelgard는 내가 만든 엔진 OFF(Open Field Framework)의 첫 번째 게임이다. 엔진과 게임을 동시에 만들고 있어서, 만들다 보면 부족한 게 계속 보인다. 몬스터 AI에 Dictionary<string, object>를 쓴 것도, 공간 쿼리에 BepuPhysics를 통째로 넣은 것도 그때는 “일단 돌아가게”가 우선이었다. 첫 게임이 이런 시행착오를 다 흡수해주는 셈인데, 여기서 잡은 것들이 엔진에 쌓이면 다음 게임은 그 수혜를 본다.
AI에게 시키기
메모리 때와 같은 방식이다. Claude Code에 이렇게 말했다:
“지금 월드 헤드리스 러너로 default월드 빠르게 한번 돌려봐 빠른 속도로, 그리고 한 10분정도. 그리고 /analyze”
지난번처럼 스킬도 만들어두라고 했다. /mem-profile이 메모리를 잡았으니, /cpu-profile이 CPU를 잡으면 된다.
프로파일링 인프라
최적화 전에 측정 도구부터 만들게 했다. 만들어진 게 SimProfiler다:
using (SimProfiler.Scope("Systems.MonsterSensingSystem"))
{
// 시스템 로직
}using 블록으로 스코프별 시간을 측정하고, ProfileScope는 stack-only struct라서 프로파일링 자체가 할당을 만들지 않는다. --profile 플래그로 HeadlessRunner를 돌리면 profile.json이 나오고, analyze-profile.py로 분석한다.
3일치 시뮬레이션을 돌려서 기준선을 잡았다:
| 시스템 | 평균 | 비중 |
|---|---|---|
| Tick 전체 | 0.598ms | 100% |
| PhysicsWorldSystem | 0.215ms | 36% |
| MonsterSensingSystem | 0.178ms | 30% |
| MonsterBehaviorSystem | 0.140ms | 23% |
| AIPlayerSystem | 0.020ms | 3% |
| PathfindingSystem | 0.019ms | 3% |
상위 3개가 전체의 89%. 여기만 건드리면 된다.
병목 4개 잡기
프로파일 결과를 AI에게 주고 최적화를 시켰다.
Monster AI LOD — idle 몬스터도 매 프레임 센싱과 행동 트리를 돌리고 있었다. 타겟이 없는 몬스터는 4프레임에 1번만 실행하게 바꾸고, 거리 비교도 sqrt 대신 distance²로. 센싱 -61%, 행동 트리 -66%.
Physics 반감 — AI가 코드를 분석하더니 “BepuPhysics가 broadphase refit만 하고 collision response는 전부 reject한다”고 했다. 3D 물리 엔진을 AABB 쿼리용으로만 쓰고 있었던 거다. raycast API도 있는데 아무데서도 안 쓰고 있었다. 이건 좀 의외였다 — 엔진 만들 때 넣어놓고 게임에서는 결국 안 썼다. 우선 Step 주기를 60Hz에서 30Hz로 줄였다.
Blackboard 박싱 제거 — 몬스터 AI의 Blackboard가 Dictionary<string, object>여서 매 접근마다 boxing/unboxing. 몬스터당 프레임당 62회, 100마리면 6,200회. struct로 교체했다.
SpatialHashGrid2D — BepuPhysics broadphase를 커스텀 공간 해시 그리드로 교체했다. O(N×M) → O(N×k). ISpatialIndex 추상화를 넣어서 게임 코드 변경 없이 구현체만 바꿀 수 있게 했다. 이게 가장 효과가 컸다.
결과
| 단계 | 틱당 평균 | 개선 |
|---|---|---|
| 기준선 | 0.598ms | - |
| Monster AI LOD | 0.412ms | -31% |
| Physics 반감 | 0.285ms | -52% |
| Blackboard → struct | 0.264ms | -56% |
| SpatialHashGrid2D | 0.151ms | -75% |
0.598ms → 0.151ms. 4배.
3일 시뮬레이션 기준 56초에서 14초.
/cpu-profile 스킬
이번에도 /mem-profile 때처럼 스킬로 만들었다:
/cpu-profile baseline # SimProfiler로 기준선 측정
/cpu-profile analyze # profile.json 분석 → 병목 리포트
/cpu-profile compare # 최적화 전후 비교다음에 성능 문제가 생기면 /cpu-profile baseline부터 시작하면 된다.
정리
SimProfiler, SpatialHashGrid2D, /cpu-profile 스킬 — 이번에 만든 것들이 엔진 쪽에 들어갔다. 메모리 때도 그랬는데, 문제를 잡을 때마다 엔진이 같이 자라는 구조다.